Azure IIS Logs in ElasticSearch
In a work context we have been working on creating an internal logging framework. This framework should be use by all projects, and provide both developers and the support team a nice status of all running applications. We currently have support for Serilog, which is using the latest durable ElasticSearch sink.
Other types of logs supported are IIS logs and Azure IIS logs. In this post I’ll describe how we send Azure IIS logs from several Azure Websites to ElasticSearch.
Background
We wanted to create a small logging framework, which would enable fellow colleagues to easily send their logging statements to an Azure hosted ElasticSearch server. This would enable the projects, and our support staff, to supervise several projects using Kibana.
We did some extensive experimenting using the LogFlow log agent. LogFlow log agent watches a specific folder and forwards logs to ElasticSearch. Actually, it can be configured to apply for several applications, which I’ll describe later in this post. Serilog has an ElasticSearch sink, which can forward log statements immediately to ElasticSearch, but we were looking for a more durable option. Therefore it seemed obvious to use LogFlow, which can forward logs already written to disk. LogFlow is an executable looking through the current folder to find any assemblies with an implementation of the Flow class. We did have a hard time making this setup work in our context. So, we wrote a custom Serilog sink, which is durable and ElasticSearch capable. We wrapped the configuration of Serilog and the sink, in a small NuGet package and made it available in our internal NuGet repository.
Now, so much for application specific log statements, it would also be a nice addition to get the IIS logs from on-premise servers and from Azure Websites in ElasticSearch as well. This would provide great insights into server health, and maybe help foresee future server issues by surveying response times and status codes.
Azure Website Logs to Azure Storage
There is a rather neat feature in Azure Websites, which might not be known by the majority of Azure users. It is actually possible to get access to Azure IIS logs. A simple option on Configure tab for the website on the Azure Portal that you would like to get the logs from:

If you click the Storage button and followed by a click on the Manage button, you’ll be presented with this dialog:
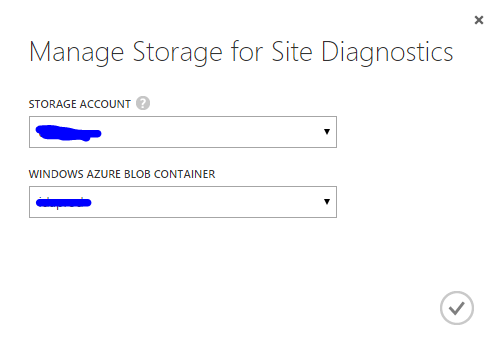
Now in this dialog you should select which storage account to push your IIS logs. The storage accounts available is the accounts that is created in the same region and under the same subscription as the website. This is important. So, if you cannot find your desired storage account, it might be because it is created in a different region or under another subscription. You also specify the name of the container in this dialog.
When this is done, you can move over to the storage account and see the content of the specified container. It will only forward new log entries, so you should maybe do some dancing on you website before any log entries ends up in the storage container as blobs.
Azure Storage to ElasticSearch
Now that our log entries are safe inside Azure Storage, we need to index them for super search capabilities. This is done in ElasticSearch.
For the client package we discarded LogFlow as log agent, but in this scenario, LogFlow is at its prime. When using LogFlow you create a class that inherit from Flow. When the LogFlow.exe is started it will look for any assemblies with implementations of Flow.
A Flow implementation contains a call to CreateProcess(), which is found in Flow base class. The CreateProcess() call initiates a fluent configuration style, which contains three overall steps, FromInput(), Then(), and ToOutput(). The FromInput() step handles in input source and how the log entries gets picked up and put into the LogFlow flow. The Then() step does some processing of the log entries and, finally, the ToOutput() step forwards the processed result.
FromInput()
LogFlow contains two build-in input processors, the ConsoleInput and FileInput. The former reads the log entries from a console and the latter from any files, using a file watcher. In our case we need an input processor that can read from Azure Storage blobs. We therefore created the StorageInput, an implementation of the LogInput class:
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading;
using LogFlow;
using Microsoft.WindowsAzure.Storage;
using Microsoft.WindowsAzure.Storage.Blob;
using Newtonsoft.Json.Linq;
namespace AzureLogForwarder
{
public class StorageInput : LogInput
{
private readonly List<CloudStorageAccount> _storageAccounts;
private readonly int _readBatchSize;
private readonly int _checkIntervalMiliseconds;
private ConcurrentDictionary<Uri, CloudBlockBlob> _blobs = new ConcurrentDictionary<Uri, CloudBlockBlob>();
private ConcurrentDictionary<Uri, BlobMetaData> _metaDatas = new ConcurrentDictionary<Uri, BlobMetaData>();
private ConcurrentQueue<Result> _unprocessed = new ConcurrentQueue<Result>();
private readonly IDictionary<string, long> _positionCache = new Dictionary<string, long>();
public StorageInput(List<CloudStorageAccount> storageAccounts, int readBatchSize = 100, int checkIntervalMiliseconds = 30000)
{
if (storageAccounts == null)
throw new ArgumentNullException("storageAccounts");
_storageAccounts = storageAccounts;
_readBatchSize = readBatchSize;
_checkIntervalMiliseconds = checkIntervalMiliseconds;
}
private void GetCurrentBlobs()
{
foreach (var account in _storageAccounts)
{
var client = account.CreateCloudBlobClient();
var containers = client.ListContainers(detailsIncluded: ContainerListingDetails.Metadata);
foreach (var container in containers)
{
if (!container.Metadata.Any() || (container.Metadata["app"] == string.Empty || container.Metadata["env"] == string.Empty))
{
// invalid container metadata, container rejected for further processing...
break;
}
var listBlobItems = container.ListBlobs(null, true, blobListingDetails: BlobListingDetails.Metadata);
foreach (var someBlob in listBlobItems)
{
var blockBlob = someBlob as CloudBlockBlob;
if (blockBlob != null)
{
var blob = blockBlob;
_metaDatas.AddOrUpdate(blob.Uri,
new BlobMetaData
{
ApplicationName = container.Metadata["app"],
EnvironmentName = container.Metadata["env"]
},
(key, value) => value);
blob.Metadata.Add("app", container.Metadata["app"]);
_blobs.AddOrUpdate(blob.Uri, blob, (key, value) => value);
}
}
}
}
return;
}
public override Result GetLine()
{
while (true)
{
Result result;
if (_unprocessed.TryDequeue(out result))
{
var fields = new JObject();
fields["app"] = result.MetaData["app"];
fields["env"] = result.MetaData["env"];
result.Json["fields"] = fields;
return result;
}
while (_blobs.Count == 0)
{
Thread.Sleep(_checkIntervalMiliseconds);
GetCurrentBlobs();
}
var blobs = _blobs.ToList();
for (int i = 0; i < blobs.Count; i++)
{
ReadLinesFromBlob(blobs[i].Key);
}
if (_unprocessed.Count == 0)
{
Thread.Sleep(_checkIntervalMiliseconds);
}
}
}
private void ReadLinesFromBlob(Uri key)
{
var cloudBlockBlob = _blobs[key];
using (var stream = cloudBlockBlob.OpenRead())
{
using (var reader = new StreamReader(stream))
{
var originalPosition = GetPosition(cloudBlockBlob.Uri.AbsoluteUri);
reader.BaseStream.Seek(originalPosition, SeekOrigin.Begin);
while (!reader.EndOfStream)
{
var result = new Result(LogContext) { Line = reader.ReadLine() };
result.MetaData[MetaDataKeys.FilePath] = cloudBlockBlob.Uri.AbsoluteUri;
result.MetaData.Add("env", _metaDatas[cloudBlockBlob.Uri].EnvironmentName);
result.MetaData.Add("app", _metaDatas[cloudBlockBlob.Uri].ApplicationName);
result.Position = reader.GetLogicalPosition();
if (reader.EndOfStream)
{
result.MetaData.Add("processed", "true");
result.MetaData.Add("etag", cloudBlockBlob.Properties.ETag);
}
_unprocessed.Enqueue(result);
}
}
}
}
private long GetPosition(string blobUri)
{
var key = "position_" + blobUri;
long position;
if (!_positionCache.TryGetValue(key, out position))
{
return LogContext.Storage.Get<long>(key);
}
return position;
}
public void SavePosition(string blobUri, long pos, bool persist)
{
var key = "position_" + blobUri;
_positionCache[key] = pos;
if (persist)
{
LogContext.Storage.Insert(key, pos);
}
}
public override void LineIsProcessed(Result result)
{
SavePosition(result.MetaData[MetaDataKeys.FilePath], result.Position, result.Position > 0);
if (result.MetaData.Any() && result.MetaData.ContainsKey("processed"))
{
CloudBlockBlob removedBlob;
_blobs.TryRemove(new Uri(result.MetaData[MetaDataKeys.FilePath]), out removedBlob);
SavePosition(result.MetaData[MetaDataKeys.FilePath], 0, true);
try
{
removedBlob.DeleteIfExists(accessCondition: AccessCondition.GenerateIfMatchCondition(result.MetaData["etag"]));
}
catch (Exception e)
{
Console.WriteLine(e);
}
}
}
}
}
With a default check interval of 30 seconds, all Azure storage accounts are iterated. Each blob found is attached an application name and environment name, found in the metadata of the container. If these are not specified on the container, the container is rejected for further processing. Then each line in the blob is read, and stored in a queue of unprocessed lines. When the overridden GetLine() is called, we pick the oldest in the queue and attaches application name and environment name to the JSON before returning. When a line is processed we persist the position, and check whether we have reached the end of the blob. If this is the case, we delete the blob and resets the position to 0. The latter is due to issues, where Azure re-creates a deleted blob for further processing. We can only delete the blob, if Azure hasn’t added more content in-between we detected end-of-blob and we try to delete it.
This implementation is pretty robust. It saves its position after reading a line and handles a possible race condition, so we don’t delete any blobs which has unprocessed lines.
One thing is to make a custom implementation of the LogInput class, another one is how to make these pieces run on Azure. We came up with the idea to run this as an Azure WebJob.
What we did was to create a free Azure Website, turn Always On, and add the output of your build as a .zip-file as a WebJob. The WebJob should be configured to run continuously. The Azure Website will unpack and start the LogFlow.exe, which will find the assembly containing our flow.
Then()
In this step we process the lines picked up in the previous step. In our case we can use the builtin IISLogProcessor. This processor will parse each line and set the correct fields with the correct values.
ToOutput()
In the final step we use the build-in ElasticSearchOutput processor. It takes an ElasticSearchConfioguration as parameter. In this configuration, we set the IndexNameFormat property and provides a ConnectionSettings instance as a parameter. Since our ElasticSearch server is using SSL, we provide a Uri instance with the correct credentials.
Summary
So, in this post I’ve outlined how we managed to get the Azure IIS logs into ElasticSearch. We use the build-in feature of Azure Websites to make them send their logs to Azure Storage. From here we pick them up using a WebJob, running on an Always On Azure Website. This WebJob uses LogFlow to process the log entries, and finally forwarding them to an Azure Virtual Machine which has an ElasticSearch server running.
If you have any comments, feedback, or what so ever, please feel free to throw us a comment below.
Tweetcomments powered by Disqus